
今回はPythonを使って、Googleキーワードプランナーのデータを使ってGoogle検索結果を自動取得するプログラムを作成しました。
ブログや自社の製品・サービスについてキーワードやGoogle検索結果などを調査するときに使ってみてください。
Googleキーワードプランナーでキーワード調査・キーワード選定を行うと、次のような各種キーワードとそれらキーワードの検索ボリューム数を得ることができます。
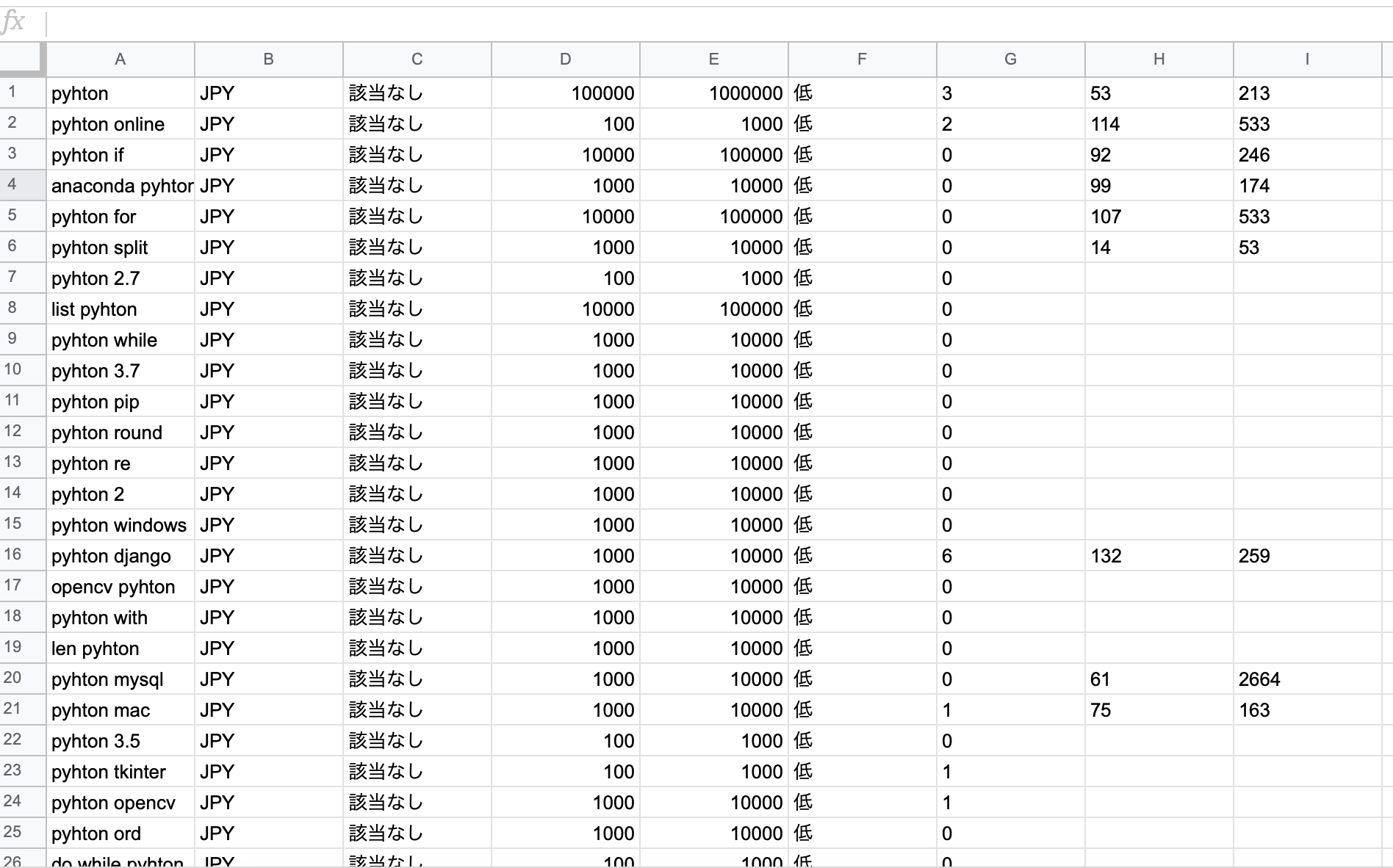
※4列目と5列目の検索ボリューム数は、キーワードプランナーからのダウンロード時には3桁ごとに,(カンマ)区切りになっているので、それを解除しておいてください。
カンマがあると後の処理で、そこで区切られてうまく表示することができません。
そして、それらのキーワードでGoogle検索結果をしたら、どのような検索結果(1ページ目)が表示されるのか調べることができます。
次の画像のようなファイルを取得することができます。
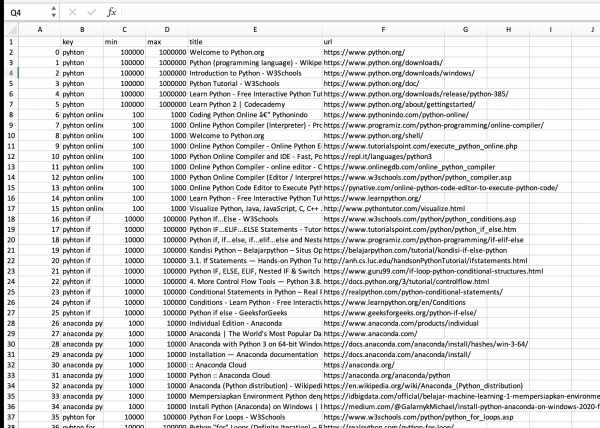
2列目:検索キーワード
3列目:最小検索ボリューム数/月
4列目:最大検索ボリューム数/月
5列目:検索結果:ページタイトル
6列目:検索結果:ページURL
使い方
Googleキーワードプランナーで得たデータ(csvファイル)をPythonプログラムと同じディレクトリ(フォルダ)に置いてください。
そして、下記プログラムで、Googleキーワードプランナーで得たデータ(csvファイル)のファイル名とプログラムを行うことによって得るGoogle検索結果のファイル名を入力して、下記プログラムを実行してください。
注意:Googleは検索結果のスクレイピングを認めていません。
サーバーに高負荷がかからなければ、黙認されている?
スクレイピングは自己責任で行ってください。
【Python】Googleの検索結果をスクレイピングするソースコードと解説
できるだけわかりやすいソースコードの紹介と解説をするために、ソースコードにはなるべく#コメントを付けています。
そして解説では各コードの説明を行っています。
※プロのプログラマの方が見ると、ひどいソースコードだなと思われると思いますが、僕のようなプログラミング初心者の方は、ソースコードの一行一行がなかなか理解しづらいので、このような形にしてみました。逆にわかりにくいかもしれませんが。。。
ソースコードを理解するためには
Pythonの知識が必要になります。
これから始めるという方は、オンラインで手軽に基礎から学べるPyQがおすすめです。
オンラインPython学習サービス「PyQ™(パイキュー)」
スクレイピングの入門本については、こちらの本がおすすめです。
Python 1年生 体験してわかる!会話でまなべる!プログラミングのしくみ
![]()

Pythonソースコード
import time
from urllib.robotparser import RobotFileParser
from urllib.parse import urlparse
import requests
from bs4 import BeautifulSoup
import pandas as pd
#必要な列に持ったDataFrameを作成
columns = ["key", "min", "max", "title", "url"]#列名
df = pd.DataFrame(columns=columns)#データフレーム作成
keyword_list = []#キーワード用リスト
mins = []#最小検索ボリューム数用リスト
maxs = []#最大検索ボリューム数用リスト
# User-Agent
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100"
#キーワードプランナーCSVファイルからキーワードを取得
with open("【キーワードプランナー】python.csv", encoding='utf-8') as f:#キーワードファイル
for row in f:
data = row.rstrip().split(",")
keyword_list.append(data[0])
mins.append(data[3])
maxs.append(data[4])
def get_html(url, params=None, headers=None):
""" get_html
#指定したURLのサイトのデータを取得
url: データを取得するサイトのURL
[params]: 検索サイトのパラメーター {x: param}
[headers]: カスタムヘッダー情報
"""
try:
# 待機
time.sleep(1)#サイトにアクセスする間隔
# データ取得
resp = requests.get(url, params=params, headers=headers)
resp.encoding = resp.apparent_encoding
# 要素の抽出
soup = BeautifulSoup(resp.text, "html.parser")
return soup
except Exception as e:
return None
def get_search_url(word, engine="google"):
""" get_search_url
検索エンジンの検索結果(URL)を取得
word: 検索するワード
[engine]: 使用する検索サイト(デフォルトは google)
"""
try:
if engine == "google":
# google 検索
search_url = "https://www.google.co.jp/search"
search_params = {"q": word}#検索ワード(word)
search_headers = {"User-Agent": user_agent}
# データ取得
soup = get_html(search_url, search_params, search_headers)#指定検索ワードでのgoogle検索結果ページのHTMLを取得。上記のget_html()関数を使用
if soup != None:#HTMLデータが空白でないならば
tags = soup.select(".r > a")#div cass = r のaタグを取得
urls = [tag.get("href") for tag in tags]#tagsからひとつずつtagを取り出す→tagからurlを取得→urlsに代入
h3_tags = soup.select(".r > a > h3")#div cass = r のaタグのh3を取得
page_titles = [h3_tag.get_text() for h3_tag in h3_tags]#h3タグのテキストを取得→リストに格納
return urls, page_titles #urls, page_titlesを返す
else:
raise Exception("No Data")
else:
raise Exception("No Engine")
except Exception as e:
return None
try:
for key, min1, max1 in zip(keyword_list, mins, maxs):
print ("{} 処理中".format(key))#処理中のキーワードを表示
urls, page_titles = get_search_url(key)#指定キーワードのGoogle検索結果のurls(複数)を取得
if urls != None:#もしurlsが空白でなければ
for url, page_title in zip(urls, page_titles):#urlsとpage_titlesからurl, page_titleをひとつずつ取得
se = pd.Series([key, min1, max1, page_title, url], columns)
df = df.append(se, ignore_index=True)
except Exception as e:
print("エラーになりました")
print(e)
#実行結果をcsvファイルで保存
df.to_csv("【結果】python.csv" ,encoding="utf_8_sig")
print("完了")
ソースコードの解説
Pandasでデータフレームを作成
#必要な列に持ったDataFrameを作成
columns = ["key", "min", "max", "title", "url"]#列名
df = pd.DataFrame(columns=columns)#データフレーム作成
Pandsライブラリを使って最終的にファイルを書き出すためのデータフレームを作っています。
pd.DataFrame()の引数columnsに列名のリストを渡しています。
キーワードプランナーCSVファイルから取得する項目を格納するリストを作成
keyword_list = []#キーワード用リスト
mins = []#最小検索ボリューム数用リスト
maxs = []#最大検索ボリューム数用リスト
ユーザーエージェント(UA)を設定
# User-Agent
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100"
ユーザーエージェント(UA)とは、Webサーバーにリクエストする際に含まれる情報で、具体的にはどのようなブラウザを使用して、どのようなOSを使っているかという情報です。
これを設定せずにrequestsライブラリのデフォルト値を使用すると、Webサーバーにブロックされる可能性があります。
キーワードプランナーCSVファイルからキーワードを取得
with open("【キーワードプランナー】python.csv", encoding='utf-8') as f:#キーワードファイル
for row in f:#csvファイルから一行ずつ取り出す
data = row.rstrip().split(",")
keyword_list.append(data[0])
mins.append(data[3])
maxs.append(data[4])
with open(“【キーワードプランナー】python.csv”, encoding=’utf-8′) as f:
with open()でファイルを開いています。
※【キーワードプランナー】python.csvの部分は、使用するファイル名に合わせて書き換えてください。
open()の引数encoding=’utf-8′
ファイルを開くときに文字コードを設定することで、文字化けを防いでいます。
for row in f:
csvファイルから一行ずつ取り出しています。
そして、取り出した行に対して、下記の処理を行っています。
data = row.rstrip().split(“,”)
rstrip()は文字列の右側の文字を取り除きます。
文字列.rstrip(取り除く文字)
※文字列の右側から「取り除く文字」に該当する文字が削除されます。
引数を省略した場合にはスペースが削除される。
.split()は、指定した文字で文字列を分割することができます。
CSVファイル(,カンマでデータが区切られたファイル)を使用しているので、引数に”,”を渡しています。
最初で延べたとおり、キーワードプランナーで得たボリューム検索数の桁数区切りを削除しておかないと、その桁数区切りで数字が区切られてうまく表示されなくなります。
この処理で、不要なスペースが取り除かれ、カンマで分割された各文字がdata(リスト)に格納されます。
keyword_list.append(data[0])
keyword_list(リスト)に、append()を使ってdataの0番目の値を追加。
mins.append(data[3])やmaxs.append(data[4])も同様です。
これをfor文を使用して、キーワードプランナーcsvファイル内のすべての行におこなっています。
URLを渡してBeautifulshopオブジェクトを取得する関数を定義(get_html)
def get_html(url, params=None, headers=None):
""" get_html
#指定したURLのサイトのデータを取得
url: データを取得するサイトのURL
[params]: 検索サイトのパラメーター {x: param}
[headers]: カスタムヘッダー情報
"""
try:
# 待機
time.sleep(1)#サイトにアクセスする間隔
# データ取得
resp = requests.get(url, params=params, headers=headers)
resp.encoding = resp.apparent_encoding
# 要素の抽出
soup = BeautifulSoup(resp.text, "html.parser")
return soup
except Exception as e:
return None
get_html(url, params=None, headers=None):
get_html関数の引数に次のものを設定
url: データを取得するサイトのURL
params: URLパラメータ(検索サイトのパラメーター)
headers: ヘッダー情報
URLパラメータとは、
URLの末尾に?をつけてそのあとに”key=value”のようにパラメーターを指定することができます。
requestsでは辞書型でパラメーターを作成してget()などの引数paramsに指定することでパラメーターを加えることができます。
time.sleep(1)
time.sleep()で()内に指定した秒数の間、プログラムの処理を待機します。
適切な時間間隔を設けることでWebサーバーへの負担を減らし、ブロックされにくくなります。
resp = requests.get(url, params=params, headers=headers)
requestのget()で引数に渡したurlのhtmlデータを取得します。
ここではurlパラメータとheaderも引数に渡しています。
resp.encoding = resp.apparent_encoding
文字化けを起こさないようにapparent_encodingで文字コードを判定してresp.encodingに格納しています。
soup = BeautifulSoup(resp.text, “html.parser”)
BeautifulSoupで取得したhtmlを解析してsoupに格納。
ここではhtmlを解析するparserとして、”html.parser”を使っています。
検索エンジン(Google)の結果を取得する関数を定義(get_search_url)
def get_search_url(word, engine="google"):
""" get_search_url
検索エンジンの検索結果(URL)を取得
word: 検索するワード
[engine]: 使用する検索サイト(デフォルトは google)
"""
try:
if engine == "google":
# google 検索
search_url = "https://www.google.co.jp/search"
search_params = {"q": word}#検索ワード(word)
search_headers = {"User-Agent": user_agent}
# データ取得
soup = get_html(search_url, search_params, search_headers)#指定検索ワードでのgoogle検索結果ページのHTMLを取得。上記のget_html()関数を使用
if soup != None:#HTMLデータが空白でないならば
tags = soup.select(".r > a")#div cass = r のaタグを取得
urls = [tag.get("href") for tag in tags]#tagsからひとつずつtagを取り出す→tagからurlを取得→urlsに代入
h3_tags = soup.select(".r > a > h3")#div cass = r のaタグのh3を取得
page_titles = [h3_tag.get_text() for h3_tag in h3_tags]#h3タグのテキストを取得→リストに格納
return urls, page_titles #urls, page_titlesを返す
else:
raise Exception("No Data")
else:
raise Exception("No Engine")
except Exception as e:
return None
Google検索を行うための基本情報
search_url = “https://www.google.co.jp/search”
基本となるGoogle検索のURL
search_params = {“q”: word}#検索ワード(word)
Google検索のパラメータ。辞書型で定義。
search_headers = {“User-Agent”: user_agent}
ヘッダー情報。
soup = get_html(search_url, search_params,search_headers)
get_html()関数で指定したURL(googole検索)、パラメータ(検索ワード)、ヘッダーを渡して、Beautifulsoupオブジェクトを取得して、soupに格納。
if soup != None:
soupにBeautifulsoupオブジェクトが格納されているか確認。
タグを指定して必要な情報を取得
tags = soup.select(“.r > a”)
div cass = r のaタグを取得してtagsに格納
urls = [tag.get(“href”) for tag in tags]
リスト内包表記を使って、
tagsからひとつずつtagを取り出す
→tagからurlを取得
→urlsに代入
h3_tags = soup.select(“.r > a > h3”)
div cass = r のaタグのh3を取得
page_titles = [h3_tag.get_text() for h3_tag in h3_tags]
リスト内包表記を使って、
h3タグのテキストを取得
→page_titlesリストに格納
return urls, page_titles
get_search_urlの戻り値として、urls(リスト), page_titles(リスト)を返す。
各キーワードのGoogle検索結果を取得
try:
for key, min1, max1 in zip(keyword_list, mins, maxs):
print ("{} 処理中".format(key))#処理中のキーワードを表示
urls, page_titles = get_search_url(key)#指定キーワードのGoogle検索結果のurls(複数)を取得
if urls != None:#もしurlsが空白でなければ
for url, page_title in zip(urls, page_titles):#urlsとpage_titlesからurl, page_titleをひとつずつ取得
se = pd.Series([key, min1, max1, page_title, url], columns)
df = df.append(se, ignore_index=True)
except Exception as e:
print("エラーになりました")
print(e)
for key, min1, max1 in zip(keyword_list, mins, maxs):
zip()を使って、複数のリストから要素をひとつずつ取り出します。
print (“{} 処理中”.format(key))#処理中のキーワードを表示
format()を使って現在処理しているキーワードをターミナルに表示します。
se = pd.Series([key, min1, max1, page_title, url], columns)
pandasのSeries()で行を作ります。
df = df.append(se, ignore_index=True)
Seriesで作った行をappend()で、データフレームに追加。
実行結果をcsvファイルで保存
df.to_csv("【結果】python.csv" ,encoding="utf_8_sig")
Pandasのデータフレームをcsvファイルで書き出します。
“【結果】python.csv”の部分は保存したいファイル名に書き換えてください。
encoding=”utf_8_sig
文字コードを指定して、文字化けを防いでいます。
EXCELファイル形式で書き出したい場合は、
df.to_csvをdf.to_excelにして、
保存名のファイル拡張子も”ファイル名.xlsx”にしてください。
参考にした情報
Python 1年生 体験してわかる!会話でまなべる!プログラミングのしくみ
![]()
Pythonクローリング&スクレイピング[増補改訂版] -データ収集・解析のための実践開発ガイド
![]()

